Distributed systems are inherently complex. This complexity introduces a range of potential failure modes that can disrupt operations, compromise data integrity, and frustrate users. Unlike monolithic systems where failures are often localized, failures in a distributed environment can cascade and propagate, making them harder to diagnose and resolve.
One of the most prevalent failure modes is node failure. This occurs when an individual node in the system, be it a server, virtual machine, or container, crashes or becomes unresponsive. The causes can range from hardware malfunctions (e.g., disk failure, power outage) to software bugs or even resource exhaustion. A single node failure might seem insignificant in a large cluster, but it can have ripple effects, especially if that node was responsible for critical tasks or held crucial data.
Related to node failure is the concept of partial failure. This is where things get particularly tricky. In a partial failure, some parts of the system are functioning correctly, while others are experiencing problems. For example, a subset of nodes might be unable to communicate with each other, or a service might be working on some nodes but not others. These situations are notoriously difficult to debug because the system is not completely down, but it’s not fully operational either. Diagnosing and resolving partial failures often requires sophisticated monitoring and diagnostic tools.
Network partitions are another common and particularly insidious failure mode. A network partition occurs when the network connecting the nodes in a distributed system is disrupted, effectively splitting the system into two or more isolated segments. Nodes within each segment can communicate with each other, but they cannot communicate with nodes in other segments. This can lead to inconsistencies and conflicts, especially if different segments continue to operate independently and make changes to shared data.
Message loss is a fundamental challenge in distributed systems. Since communication relies on sending messages over a network, and networks are inherently unreliable, messages can get lost, delayed, or even delivered out of order. This can lead to inconsistencies, data corruption, or unexpected behavior if the system is not designed to handle such scenarios. Employing techniques like acknowledgments, retries, and idempotent operations is crucial for mitigating the impact of message loss.
Byzantine failures represent a more sinister class of failures. In this scenario, a component of the system, such as a node or a process, starts behaving arbitrarily, potentially sending incorrect or malicious messages to other components. This can be due to software bugs, hardware faults, or even deliberate attacks. Dealing with Byzantine failures requires specialized algorithms and protocols, such as Byzantine fault tolerance (BFT) algorithms, which are designed to reach consensus even in the presence of malicious actors. These add complexity.
This image is from Cloudflare’s analysis of their availability incident in November 2020:
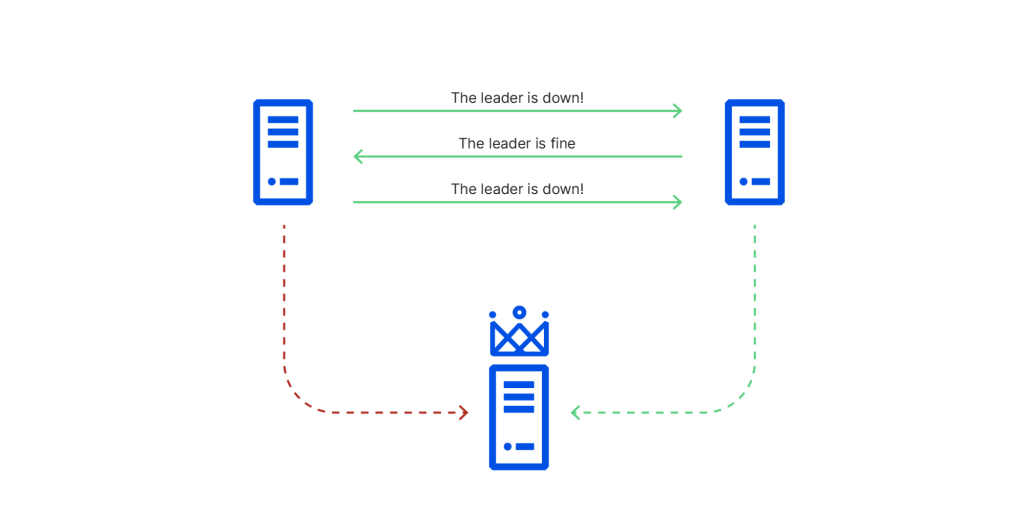
Finally, cascading failures are a particularly devastating type of failure mode. This occurs when an initial failure in one part of the system triggers a chain reaction of failures in other parts. For example, a failing database server might cause increased load on other servers, leading to their eventual failure as well. Cascading failures can quickly bring down an entire distributed system if not properly addressed. Careful design, load balancing, and fault isolation mechanisms are essential for preventing cascading failures.
In conclusion, distributed systems are susceptible to a variety of failure modes, ranging from simple node crashes to complex Byzantine failures and devastating cascading failures. Understanding these potential pitfalls is essential for designing and operating resilient distributed systems.